
Personalizing Information Retrieval using Evolutionary Modelling
Researchers and students need information retrieval tools that will support them in their work. To provide effective support, such tools must be able to track changing interests and automatically suggest new, possibly unrelated, information that might be helpful. This article describes an approach to representing a user interest profile using a genetic algorithm, a form of evolutionary model. The profile is maintained with user feedback and genetic operators and initial testing with a database of academic journal abstracts has found this to be a promising technique.
1. Introduction
This article describes an approach to representing a user’s interest profile using an evolutionary model in its early stages of research. The representation of the profile, how it is updated by user feedback and the basic genetic operators reproduction, crossover, and mutation are described. The role the advanced operators dominance and reordering will play in future work is outlined. A database of academic journal abstracts relating to Human- Computer Interaction (HCI) that has been developed to provide a static test bed for evaluation of the evolutionary model is described. Finally, future development of the profile with the introduction of interest categories and new information sources are described.
2. Background
Researchers and students need information retrieval tools that will support them in their work on projects, papers, and research. The Internet is a vast gold mine of information but the sheer quantity of information means that it is becoming more difficult to find relevant information. The Internet user community is growing rapidly every day as more and more information seekers and providers come on-line. As more information becomes available, people are becoming more overwhelmed with information overload. They cannot possibly keep track of all this information or its sources.
The original and most basic Internet information tools are electronic mail (“email”), Usenet news (“news”), and the file transfer protocol (“ftp”). These have been joined in recent years by wide area information servers (“wais”), gopher, and the world wide web (“www” or “web”); see Gilster (1993). One of the goals of the Electronic Learning Facilitator (ELF) project at Heriot-Watt University is to automate the discovery of new information sources (Kirby et al 1993). The goal of this work is to exploit information sources that are already known.
2.1 Profile Modelling
A useful information retrieval system for students and researchers should be able to keep track of their changing interests in an interest profile. Modelling user interests is a long term approach. The profile is updated by continuous user interaction over a period of time allowing the profile to learn about the interests of the user. Using this profile, the information retrieval system should be able to make suggestions about information that the user might find interesting and helpful. Automated suggestions should reduce the need for users to query Internet sources directly thus reducing their workload. Any reduction, however small, will be beneficial. However, if many irrelevant suggestions are produced, the user may waste time reading such information; a balance must be struck.
In information retrieval, this balance is measured by the rates of recall and precision (van Rijsbergen 1979). Recall measures the amount of relevant information retrieved whereas precision measures the relevance of retrieved information. Ideally these should both equal 1, i.e. everything relevant is retrieved and everything retrieved is relevant.
2.2 A Genetic Approach
A genetic algorithm was considered a promising technique to implement an interest profile for several reasons. Firstly, user profile modelling is, in a sense, an optimization problem; the number of useful suggestions should be maximized. However, there is no single piece of information or a set of information that will satisfy the users long term needs because their needs change over time.
Secondly, the random recombination and introduction of new information performed by a genetic algorithm should lead to suggestions of new, possibly unrelated, information that might be helpful. Even if the information is not helpful, the user can provide feedback to update the profile.
Thirdly, a genetic algorithm has been applied in an information filtering context for Usenet news with reasonable success (Sheth & Maes 1994).
3. The HCI Bibliography System
The HCI Bibliography system is a simple information retrieval system containing 500 academic journal abstracts relating to HCI. The system is written in C++ and uses the world wide web browser, Netscape, for its user interface.
The HCI Bibliography system was created for two specific reasons. Firstly, to combine an information retrieval system and a genetic algorithm and secondly, to provide a static test bed for initial testing and evaluation of the evolutionary model.
The HCI Bibliography uses a simple vector space model in which documents (the abstracts) and queries are represented as vectors (Wong et al 1987). Documents are scored for relevance with queries by finding the dot product of each document vector and the query vector. The results are presented in descending score order.
4. Representing the Profile
An interest profile is represented and maintained using an evolutionary model consisting of a population (P) of individuals (I):
P = { I1, I2, …, In }
Each individual consists of a fitness value (F) and a set of genes and is responsible for a small area of the search space. A gene consists of a term (T) and its associated weight (W):
I = { F, (T1, W1), (T2, W2), …, (Tm, Wm) }
The weight of a term may be positive or negative and represents the importance of the term in the profile. The weight is used when scoring a document against a query generated by an individual (see section 4.1). This is an example of real parameter coding, i.e. the genetic operators work on the terms and weights themselves rather than a coded representation, e.g., binary coding. An example profile is:
P = {
I1 = { 2, (ADAPTIVE, 3), (TECHNOLOGY, 5), (COMPUTER, 1), (INTERFACES, 1) },
I2 = { 4, (ERROR, 7), (BASED, 1), (COMPUTER, 5), (ADAPTIVE, 1), (INTERFACES, 1) },
I3 = { 6, (INTELLIGENT, 2), (USER, 1), (INTERFACES, 10), (ADAPTIVE, 1), (COMPUTER 1) }
…
}
The fitness value (F) of an individual measures how effective it is in retrieving relevant information for the user. The fitness value is updated by user feedback (see section 6). The following diagram shows how the profile is updated by user feedback and evolution.
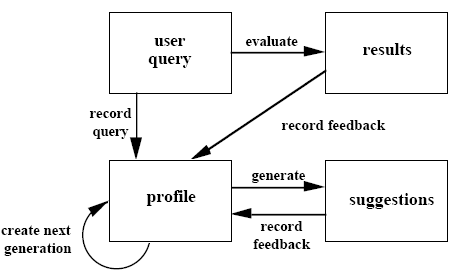
4.1 Making Suggestions
The user can ask for the system’s suggestions of interesting information. A query is generated for each individual in the profile. For example, individual I:
I = { 2, (ADAPTIVE, 3), (TECHNOLOGY, 5), (COMPUTER, 1), (INTERFACES, 1) }
would produce the query:
ADAPTIVE TECHNOLOGY COMPUTER INTERFACES
with the weight of each term used to produce the vector representation of the query.
The profile-generated queries are evaluated, the results collated, and duplicates removed. The results are presented in the same way as those from a user generated query.
5. The Genetic Algorithm
A typical genetic algorithm is a cycle of reproduction, crossover, and mutation that continues until some fitness criteria is achieved. This cycle is not suitable for the suggestions mechanism of an information retrieval system. The fitness of an individual is determined by the feedback from the user on the information it retrieves. It would obviously be unreasonable for the user to provide feedback for the information retrieved by each new generation produced in a traditional cycle. However, such a cycle is not required in this application.
Profile modelling requires much less change across generations than typical genetic algorithm applications. Users will concentrate on one general area while working on a report or project, for example, so a large proportion of the profile will be stable. This application of a genetic algorithm is best described as a slow evolution of a population continually adapting to environmental changes rather than as a directed search. Variety must be introduced, of course, using the random recombination of crossover and the introduction of new information by mutation.
Rather than continuously producing new generations until some fitness criteria is achieved, a new generation is produced after each user query. This does not reduce the power of the genetic algorithm approach because each individual learns during its lifetime from relevance feedback from the user (see section 6). Consequently, the size of the population is smaller than typical genetic algorithm applications; a constant population of 10 individuals is used at present. Having a larger population than absolutely necessary would tend to produce far too much information for the user to look at.
5.1 Creating the Next Generation
Initially, the reproduction process was based on the simple biased roulette wheel (Goldberg 1989). All the individuals in the population were replaced with a crossover rate of 1 and a mutation rate of 0.01. This was found to be unsuitable because the stability required in the profile to represent stable user interests was not maintained.
The stability in the profile is now maintained by the stability rate, S. The individuals in the population are ranked by fitness and a proportion S of the top ranked individuals are retained for the next generation. A proportion 1-S of new individuals are required. This requirement is met by individuals produced by crossover at the crossover rate, C, and those produced by mutation at the mutation rate, M, as shown below.
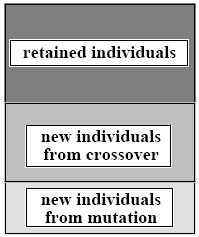
The new individuals are chosen for crossover and mutation from the population using the biased roulette wheel method. Whether or not the new individuals should be chosen from the individuals not in the top proportion S only will be investigated in the future. The sum of the rates of stability, crossover, and mutation is always 1. The current rates are S = 0.4, C = 0.4, M = 0.2.
5.2 The Basic Operators
The mutation operator changes a random term for a randomly chosen alternative term. In the HCI Bibliography system, alternative terms are chosen from those occurring in the abstracts database. However, when Internet information sources are introduced, a different source of alternative words will have to be found.
Single point crossover is applied to two parent individuals:
I1 = { F, (T1, W1), (T2, W2), (T3, W3), (T4, W4), (T5, W5), (T6, W6), (T7, W7) }
I2 = { F, (T1, W1), (T2, W2), (T3, W3), (T4, W4), (T5, W5), (T6, W6), (T7, W7) }
I1'; = { F, (T1, W1), (T2, W2), (T3, W3) (T4, W4), (T5, W5), (T6, W6), (T7, W7) }
I2'; = { F, (T1, W1), (T2, W2), (T3, W3), (T4, W4), (T5, W5), (T6, W6), (T7, W7) }
5.3 The Advanced Operators
The dominance and reordering operators are not used at present but will incorporated in future work. Dominance allows each gene to have multiple values; the value chosen being the one with the highest weight. This creates a “memory” distributed throughout the population which is potentially useful in this application. The standard example used to explain dominance is that of butterflies with ancestors having red wings being able to adapt more quickly as their environment changes from green to red than those without (Goldberg 1989). Correspondingly, the user profile should be able to adapt more quickly to interests that it has seen before when the user returns to them than new interests.
Reordering overcomes the problem of the crossover operator destroying building blocks. For example, the terms ADAPTIVE and INTELLIGENCE are the most important terms in I and constitute a building block:
I = { 5, (ADAPTIVE, 20), (USER, 4), (INTERFACE, 6), (INTELLIGENCE, 8) }
The high defining length of 3 of schema S (where * is the “don’t care” symbol):
S = { 5, (ADAPTIVE, *), *, *, (INTELLIGENCE, *) }
increases the likelihood that S will be destroyed by crossover. Rearranging I to reduce the defining length to 1, for example, decreases the likelihood that S' will be destroyed:
S'; = { 5, (ADAPTIVE, *), (INTELLIGENCE, *), *, * }
This will produce I':
I';= { 5, (ADAPTIVE, 20), (INTELLIGENCE, 8), (USER, 4), (INTERFACE, 6) }
Reordering searches for better gene ordering at the same time as searching for better individuals.
6. User Feedback
User feedback is essential to tell the system how well it is performing, i.e. how relevant the information it retrieves is to the user. Information retrieval systems require as much feedback information as possible. However, it is desirable that the feedback is collected automatically without the user having to take further action. Finding ways of automatically collecting feedback information is one of the sub-goals of this work. In the HCI Bibliography system, feedback can be obtained from the user in three ways:
- recording user queries
- recording which abstracts the user looks at
- explicit marking of an abstract as relevant
6.1 Recording User Queries
User queries are a direct source of information about what the user is interested in. Each of the terms in the query are added to each individual in the profile with a small positive initial weight of 1. If an individual already contains a term then its weight in that individual is incremented by 1. For example, adding the query terms:
ADAPTIVE COMPUTER INTERFACES
to the profile P:
P = {
I1 = { 2, (ADAPTIVE, 2), (TECHNOLOGY, 5) },
I2 = { 4, (ERROR, 7), (BASED, 1), (COMPUTER, 4) },
I3 = { 6, (INTELLIGENT, 2), (USER, 1), (INTERFACES, 9) }
}
would produce the profile P':
P' = {
I1 = { 2, (ADAPTIVE, 3), (TECHNOLOGY, 5), (COMPUTER, 1), (INTERFACES, 1) },
I2 = { 4, (ERROR, 7), (BASED, 1), (COMPUTER, 5), (ADAPTIVE, 1), (INTERFACES, 1) },
I3 = { 6, (INTELLIGENT, 2), (USER, 1), (INTERFACES, 10), (ADAPTIVE, 1), (COMPUTER 1) }
}
This increases the importance of the query terms in the profile by spreading them over all the individuals.
An alternative is to make a new individual from the query terms and add it to the population. This was initially rejected because it would not increase the importance of the query terms throughout the profile. The new individual may not be selected for reproduction because it would have the initial fitness value of all new individuals of 1. Thus all the new information would be lost because it would not be carried through to the next generation. This can be overcome by giving it a high initial fitness value. This approach will be tried because spreading the query information throughout the profile to every individual tends to make each individual contain the same thus loosing variety in the population.
Recording user queries is a method of obtaining feedback requiring no extra input from the user.
6.2 Recording Which Abstracts the User Looks At
Although looking at an abstract does not mean it is relevant it does give some indication that it might be. Sheth & Maes (1994) suggested that the time the user spends looking at a result from an information retrieval system would determine how relevant it is. This idea is unworkable because it assumes that viewing a result is a structured sequence of actions:
- open the dialogue to read the result
- read the result
- close the dialogue when finished reading
This takes no account of any interruptions the user may have, e.g. a telephone call or that the user may be comparing the information on the screen with information on paper which would lengthen the time spent reading the result. Further, having the information on the screen does not mean the user is actually reading 100% of the time. This method of obtaining user feedback also requires no extra input form the user. No use is made of this feedback in the present system.
6.3 Explicit Marking by the User
When viewing retrieved abstracts using the HCI Bibliography system, each abstract has a radio box with options Relevant and Irrelevant. By selecting one of these the user is explicitly stating, in as simple a form as possible, that the abstract is relevant or irrelevant, respectively.
When the user provides feedback for an abstract retrieved by a system suggestion, the individual in the profile that produced the query that retrieved it must be updated. The terms in the title of the abstract are added to the individual that retrieved it. If the feedback is positive and a term was not already present in the individual, it is added with a small positive initial weight of 1. If the feedback was negative, then the initial weight would be -1. If a term is already present in the individual then its weight would be incremented by 1 for positive feedback and decremented by 1 for negative feedback. The fitness value of the individual is incremented by 1 for positive feedback and decremented by 1 for negative feedback.
For example, adding the abstract title terms:
INTELLIGENT USER INTERFACES MODELLING
to individual I:
I = { 5, (INTELLIGENT, 3), (USER, 2), (INTERFACES, 9) }
with positive feedback would produce individual I':
I'; = { 6, (INTELLIGENT, 4), (USER, 3), (INTERFACES, 10), (MODELLING, 1) }
and, with negative feedback, would produce individual I'':
I'; = { 4, (INTELLIGENT, 2), (USER, 1), (INTERFACES, 8), (MODELLING, -1) }
7. Further Work
In typical genetic algorithms, mutation plays a very small role. In this application, however, a high mutation rate might be beneficial because it would introduce more new information into the profile. Experimentation with all these parameters will be made in future work.
7.1 Interest Categories and Information Sources
User interests naturally fall into different categories. For example, within the field of computer science categories of interest may be user interfaces, databases, and genetic algorithms. Categories also naturally divide into sub-categories; user interfaces dividing into adaptive interfaces, user evaluation, and graphic design. Users may want to set up a different category for each project or paper they are working on, for example. Future development will allow users to set up different interest categories. It is important to understand the relationship between interest categories and information sources and how they affect the search process and therefor the representation of the profile.
Since the aim of this work is to produce an information retrieval system for the Internet, information sources including wais and www will be introduced. Information sources have two basic characteristics; the range or diversity of information they contain and whether they are static or dynamic.
In the following diagram, (a) shows a single interest category taking its information from a single information source. The current HCI Bibliography system follows this model.
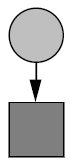
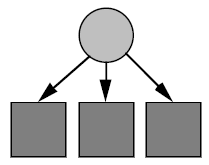
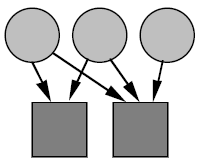
In the diagram above, (b) shows multiple categories taking information from a single source. The range of information from a single source determines whether a category should be represented by an individual or a population. If the source contains a very large amount of information covering an entire topic then it would be suitable to represent a category by a population. If the source is not so diverse, then a single individual may be more suitable.
Also in the diagram above, (c) shows multiple categories taking information from multiple sources. The characteristics of each information source is important, i.e. whether the source is static (or changes very slowly) or dynamic. So, for example, roughly the same effect may take place if a category takes information from a single dynamic wide ranging source as with many static narrow sources. The effects of the representational and searching power of the profile on the combinations of interest categories and source characteristics must be researched.
8. Conclusions
Initial testing of the evolutionary model shows it is a promising technique. However, it is at a very early stage of research and there is much more work to be done. As discussed above, it is important to understand the relationship between interest categories, information sources, and populations and individuals in the search process. Once these new information sources and interest categories have been introduced, full scale user testing can begin.
References
- Gilster, Paul 1993. The Internet Navigator. John Wiley & Sons.
- Goldberg, David E. 1989. Genetic Algorithms in Search, Optimisation, and Machine Learning. Addison-Wesley.
- Kirby, R. B., J. T. Mayes, P. McAndrew, A. C. Kilgour, and H. Taylor. ELF: The Electronic Learning Facilitator.
- Sheth, Beerud D., and Pattie Maes. Evolving Agents For Personalised Information Filtering. Proceedings of AAAI ‘93, July 1993.
- Wong, S. K. M., W. Ziarko, V.V. Raghavan, and P. C. N. Wong. On Modelling of Information Retrieval Concepts in Vector Spaces. ACM Transactions on Database Systems. 12(2):299-321.
- van Rijsbergen, C. J. 1979. Information Retrieval, Second Edition. Butterworths.