
Maintaining Document Mental Models by Reorganizing Document Files
In The Myth of the Paperless Office, Abigail Sellen and Richard Harper explore why paper use is increasing despite the predictions of its demise at the hands of the electronic office. One key advantage of paper documents over electronic documents is the way paper documents enable us to deal with corrupted or missing pages. For example, if my printer runs out of toner after printing the first ten pages of a fifty page document, I can read the ten pages I do have; I don’t have to wait for the remaining forty pages to print before starting to read the document. However, if the transfer of an electronic document is interrupted, my word processor cannot read the part of the document file that has been transferred successfully because current software needs the complete file. Similarly, paper documents corrupted with dirt and coffee stains are still readable whereas corrupted document files are not. Paper documents can tolerate errors when electronic documents cannot because each page of a paper document is a complete unit. In contrast, the location of the content of each electronic-document page depends on the organization of the file.
Document viewing and editing software presents document files as a series of individual pages, just like their paper counterparts:

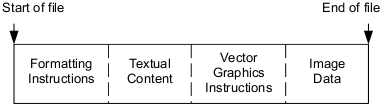
These applications shield users from the organization of the data in the document files, which is often quite different from the sequence of pages they present. For example, a word processor might store formatting instructions at the beginning of a file followed by the text of the document, the instructions for vector graphics, and then any other information such as images.
Although applications conceal the complexities of document file organization from users in normal use, these complexities are exposed when the transfer of document files is interrupted or when they become corrupted. For example, if the transfer of the following document file is interrupted at point A, all of the formatting instructions have been transferred but because so little of the text has been transferred, the formatting instructions are useless.
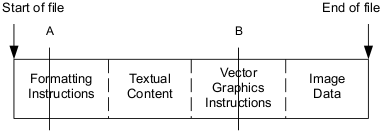
Similarly, if the file is corrupted at point B, all the text and formatting instructions are available, but they cannot be used because the file in incomplete. This breaks our mental model because it is not the way paper documents behave.
To maintain our document mental model, operating systems and applications should not need a complete file and should be able to use the partial information that is available. Ideally, if 20% of a fifty page document file has been downloaded when its transfer is interrupted, the first ten pages should be available as a ten-page document. To give operating systems and applications this flexibility, we need to reorganize the contents of document files.
We can maintain our mental model of a document as a sequence of pages by organizing document files as a sequence of units:

The amount of information stored in each unit depends on the resolution of the file. Low-resolution files might store a whole section in a single unit, whereas high-resolution files might store a paragraph or a sentence in each unit. Most documents would likely have a medium resolution, which would store one page in each unit.
Each unit contains all the information required to render the content of the unit. For example, a unit that represents a page of a company report would contain all the text, layout and formatting instructions, and images that present the financial charts and graphs on the page. The following example shows a three-page document organized into three units, one unit per page. The first unit contains all the text, formatting and vector graphics information required to render the first page; the second unit contains the text and images on the second page; and the third unit contains the text and formatting instructions for the third page.
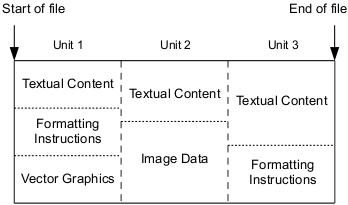
The content of each unit must be independent of succeeding units but does not need to be independent of preceding units. In fact, efficient implementations would take advantage of the accumulation of information over a sequence of units. For example, the unit that contains the first page to use the top-level heading style, say bold 24pt Helvetica, would also include the definition of the top-level heading. Each subsequent unit that contains a page with a top-level heading would re-use the definition supplied by the earlier unit.
By organizing document files as a series of self-contained units, every complete unit that has been transferred contains a useful and usable part of the document. If the transfer of a document file organized into units is interrupted in the middle of downloading a unit, or if a unit becomes corrupted, that unit is unusable because it is incomplete. However, all the preceding units that have been downloaded are usable. This ensures that the maximum amount of information in a document file will be usable if its transfer is interrupted or if it becomes corrupt. In the following example, interrupting the transfer at point A leaves us with the first unit, which might be the first sentence, paragraph or page, depending on the resolution of the file.
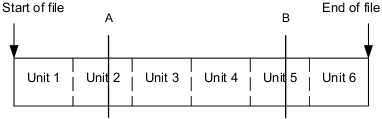
Similarly, if the file is corrupted at point B, we have the first four units which completely describe the information required to display the first four sentences, paragraphs or pages, depending on the resolution.
In the case of a corrupted unit, the software would search for the start boundary of the following unit to attempt to read the remaining units, in the same way that compilers attempt to parse the source code that follows a syntax error. In the best case, every unit preceding and succeeding a corrupt unit would be usable.
As well as maintaining our document mental model, organizing a document file as a sequence of units enables progressive downloading: as each unit is transferred, the software can render the information in the unit while downloading the remaining units. Progressive downloading gives users the impression that a document is downloading faster than it actually is.