
Improving Information Retrieval System Performance with Concepts
The goal of an information retrieval system is to maximize the number of relevant documents returned for each query. Keyword information retrieval systems often return a proportion of irrelevant documents because matching keywords is imprecise: words can have different meanings when used in different contexts, and a single idea can often be expressed by several different words or synonyms. Information retrieval systems can be made more precise by matching concepts, keywords for which the intended meaning has been identified, either with information from a lexicographic database in the case of documents, or by asking the user to choose one meaning from several possible meanings in the case of queries. This article describes the algorithms and data structures needed to implement a concept IR system, how concepts can be used to enhance keyword queries, and describes a prototype user interface for a concept information retrieval system.
1. Introduction
The goal of an information retrieval (IR) system is to maximize the number of relevant documents returned for each query. The results returned by keyword IR systems often contain a proportion of irrelevant documents because matching keywords is imprecise. The imprecision is caused by two characteristics of natural language: words can have different meanings when used in different contexts, and a single idea can often be expressed by several different words or synonyms.
The proportion of relevant documents retrieved by an IR system can be increased by decreasing the amount of ambiguity. One way to reduce the ambiguity is to match the intended meanings of the keywords. The intended meaning of keywords are represented by concepts, keywords for which the intended meaning has been identified, either with information from a lexicographic database in the case of a document, or by asking the user to choose one mean from among several possible meanings in the case of queries.
This article describes the algorithms and data structures needed to implement a concept IR system, and describes a prototype user interface for such a system. Section 2 explains in more detail why keyword matching algorithms are imprecise, and section 3 describes why matching concepts rather than keywords will produce more accurate IR systems. Section 4 describes how concepts can be used to enhance keyword queries, and section 5 describes the concept IR model. Finally, section 6 describes a user interface prototype for a concept IR system.
2. The Imprecision of Keyword Matching Algorithms
The matching algorithms used by keyword IR systems are imprecise and retrieve irrelevant as well as relevant results. Two causes of this imprecision are terminology and semantics, both aspects of natural language. Terminology affects retrieval because different people use different words for the same concept (Furnas et al. 1987). Terminology is often cultural; a pavement in the UK is a sidewalk in the US, for example.
Semantics affects retrieval because the text of a document may not contain the exact keywords in the query but may nevertheless be about the topic of interest. This problem is exacerbated by polysemy. Polysemous words have different meanings in different contexts. For example, Java can refer to the Island in Indonesia, a type of coffee, coffee itself, or the object-oriented programming language. Matching a word does not identify the context in which it is used.
The polysemous meanings, or senses, of words can lead to keyword queries that are ambiguous. IR systems are unable to differentiate between the different senses of a keyword and retrieve documents that contain all the senses. Although the results are what the user asked for in the query, the results are often not what the user intended. A proportion of the results will be irrelevant to the intended sense and users must expend effort evaluating the results for relevance.
The next section describes how identifying the intended meaning of keywords can improve the precision of IR systems.
3. Concepts
The ambiguity inherent in matching keywords can be eliminated by identifying the meaning that a document or query author intended when they used a keyword. In this article, a concept is a disambiguated keyword, i.e. a keyword for which the intended meaning has been identified.
Queries contain a small number of keywords, some of which might have more than one meaning. It is relatively straightforward to present the user with a list of possible meanings for an ambiguous keyword and ask him or her to select which meaning was intended. This choice should be optional to reduce the burden on the user, but the effort will be rewarded by more accurate results. Identifying the concepts present in the documents in a collection must obviously be automated.
To be able to identify the concepts in a document collection, and to be able to present users with a choice of possible meanings for a keyword, a concept IR system must have knowledge of those possible meanings. One such repository of word meanings is a lexicographic database. The examples in this article use WordNet, an on-line lexical reference system developed by lexicographers (Miller et al. 1993, Fellbaum 1998). WordNet organises English nouns, verbs, and adjectives into synonym sets that represent one underlying lexical concept. This article only considers nouns for simplicity.
WordNet enables the senses of a keyword to be disambiguated. For example, WordNet defines three senses of the (noun) keyword Java:
- an island in Indonesia south of Borneo;
- a beverage consisting of an infusion of ground coffee beans;
- a platform-independent object-oriented programming language used for writing applets that are downloaded from the World Wide Web and run on the client’s machine.
The definition of a concept used in this article is a keyword and the number of the WordNet sense that identifies its meaning. For example, java/1 represents the first sense, an island is Indonesia.
WordNet also provides access to the concept trees that describe the relationships between concepts in the database. In this article, two concepts, A and B, are connected by five relations:
- synonymy represents the same-as relationship (A EQUALS B);
- hyponymy represents the generalization relationship (A IS-A B);
- hypernymy represents the specialization relationship (B IS-A A).
- meronymy represents the part-whole relationship (A IS-PART-OF B).
- holonymy represents the is whole-part relationship (B IS-PART-OF A).
Concept trees show how the concepts in WordNet are connected with these relations. The following diagram illustrates the structure of a concept tree. The generalizations show the concepts that can be reached with the hyponym relation. The specializations show the concepts that can be reached with the hypernym relation.
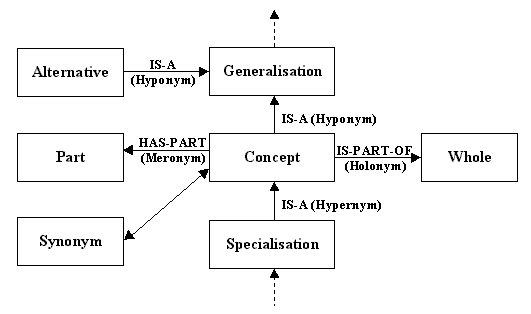
Some concepts are composed of parts or are made from substances. The parts or substances of a concept are reached with the meronym relation. Some concepts are part of a whole and the concept that represents the whole is reached with the holonym relation.
The alternatives of a concept are those concepts that have the same generalization as the concept, i.e. the siblings of the concept in the tree. Alternatives are reached with the hyponym relation.
The following diagram shows the partial concept tree of the first sense of Java, the island in Indonesia. This is a partial concept tree because it only shows a small number of the potentially huge number of concepts that can be reached with the five relations. Two levels of generalization are shown: Java is an island and an island is a type of land. There are no specializations of this sense of Java. Three example alternatives are the concepts Bermuda, Ceylon, and Singapore that have the same generalization as Java, Island.
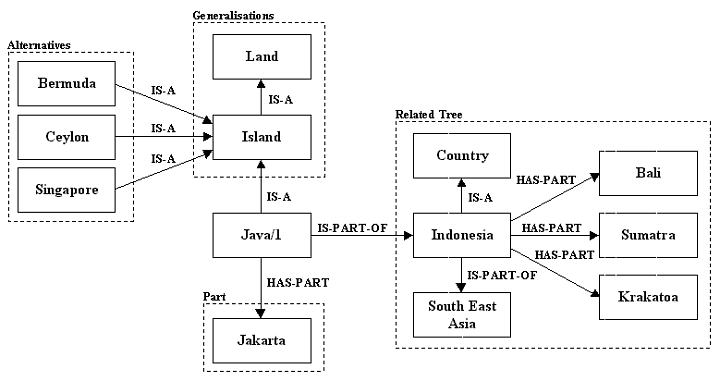
WordNet stores a single part of this sense of Java, the concept that represents its capital city, Jakarta. The diagram above also shows the concept tree of the related concept Indonesia. Indonesia is a country that is part of South East Asia and is made up of several parts that include Bali, Sumatra, and Krakatoa, as well as Java.
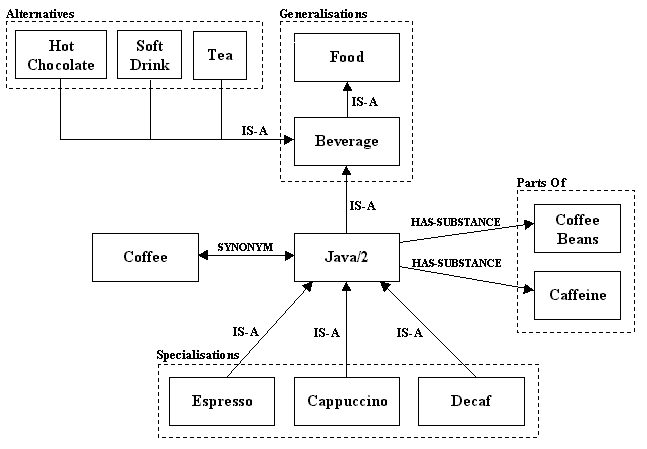
The following diagram shows the partial concept tree of the second sense of Java, the beverage. Two generalizations are shown: coffee is a type of beverage and beverage is a type of food. Three specializations of coffee are shown: espresso, cappuccino, and decaf are types of coffee. Three example alternatives are shown: hot chocolate, soft drink, and tea share the same generalization as Java, beverage. Coffee is made of two substances, coffee beans and caffeine.
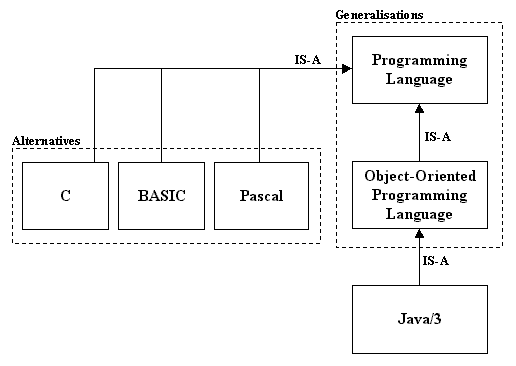
The following diagram shows the partial concept tree of the third sense of java, the object-oriented programming language. Two generalizations are shown: Java is an object-oriented programming language which is a type of programming language. There are no specializations or alternatives to this sense of Java (WordNet stores information on only one object-oriented programming language). The alternatives for the generalization of object-oriented programming language, programming language, are shown: C, BASIC, and Pascal are all types of programming language.
The next section describes how the information stored in concept trees can improve the performance of keyword IR systems by making keyword queries more specific.
4. Enhancing Keyword Queries with Concepts
Keyword IR systems retrieve documents by matching the keywords in the query with the keywords in the documents. A simple data structure that maps keywords to documents is an inverted index (van Rijsbergen 1977). Each keyword (Ki) is listed in an index and points to a list of the documents (Di) that contain the keyword:
- K1 ⇒ D1, D2, D3, D4
- K2 ⇒ D1, D2
- K3 ⇒ D1, D2, D3
- K4 ⇒ D1
The Boolean query model is one of the oldest IR models and will be used to illustrate how keyword queries can be enhanced with concepts. The Boolean query model joins the keywords in a query with the logical connectives AND (∧), OR (∨), and NOT (¬) (Lefkowitz 1964). The Boolean model uses an index to retrieve documents that answer queries such as:
Q = (K1 ∧ K2) ∨ (K3 ∧ ¬ K4)
To satisfy the (K1 ∧ K2) part we intersect the K1 and K2 lists, to satisfy the (K3 ∧ ¬ K4) part we subtract the K4 list from the K3 list. The ∨ is satisfied by taking the union of the two sets of documents. The result is the set {D1, D2, D3} which satisfies the query.
Although Boolean queries are powerful, they are difficult to write when more than a few logical connectives are involved (Green 1990). Boolean queries can be used more effectively if they are generated automatically by an IR system to represent concepts chosen by the user. The concept browsing user interface described in section 6 in one method of selecting concepts.
Query expansion is one automated technique that has been used to address the imprecision of text retrieval techniques (Spink 1994). Query expansion adds keywords to a query that are related to the keywords supplied by the user, such as the synonyms of the keyword. For example, if the original query contains a single keyword, K, the synonyms of the keyword are added as disjunctions. The query,
Q = K
is expanded to incorporate the synonyms Si of K:
QE = K ∨ S1 ∨ S2
Adding the synonyms helps to overcome the problem of different words being used for the same concept. Automatic methods of choosing synonyms are required because users find it difficult to come up with alternative search terms (Ruge 1995).
Query expansion techniques can be enhanced with concepts to make the expanded queries more specific. Once the keywords in a query have been disambiguated into concepts, the keywords relating to the generalizations, specializations, and the parts of the concepts can be added to the query.
For example, the simple query
Q = java
must be disambiguated by asking the user which of the three senses of Java is intended. The keywords in a query can be disambiguated by presenting a list of the senses of each keyword and enabling the user to select the intended senses.
Disambiguating a keyword by selecting one sense over the other senses indicates that documents containing the other senses should not be retrieved. If query Q is disambiguated into sense 3, the object-oriented programming language, then documents about the island or the beverage should not be retrieved. This requirement can be met by ensuring that documents containing the synonyms, specializations, generalizations, etc. of the other senses are not retrieved. This translates into a query such as:
QE = java ∧ ¬(jakarta ∨ indonesia ∨ bali) ∧ ¬(espresso ∨ caffeine ∨ tea)
This query requests documents that contain the keyword Java but not the keywords that relate to the two senses of Java that are not required: the island and the beverage. The keywords that represent the island are one of its parts, Jakarta, the whole of which Java is a part, Indonesia, and another part of Indonesia, Bali. These are a selection of the keywords that might be present in a document about Java the island. The keywords that represent the beverage are a type of coffee, espresso, a substance that is part of coffee, caffeine, and an alternative to coffee, tea. These are a selection of the keywords that might be present in a document about Java the beverage.
This section described how keyword matching algorithms can be made more accurate with concepts. The next section describes how matching the concepts in queries with the concepts in documents can produce an even more effective IR system.
5. The Concept IR Model
The concept IR model proceeds in three stages: the concepts in each document in the collection are identified, the concepts in a query are identified, and the query concepts are matched with the document concepts. These three stages are now described in more detail.
5.1 Identifying Document Concepts
The first stage in the concept IR model is to identify the concepts in the documents in the collection. An index must be built that maps concepts to documents to enable fast retrieval. This process need only be done once for each document added to the collection. The index can be updated incrementally as each new document is added to the collection.
The concepts in a document are identified by first extracting the keywords and removing the duplicates and stop words. Each keyword is then added to a list of concepts. A keyword with more than one sense must be disambiguated before being added to the list of concepts. Five tests are performed to identify which sense of a keyword is present in a document. A point is awarded if any of the following conditions are met:
- one or more of the synonyms of the sense occur in the document;
- the sense is a part of a concept that occurs in the document;
- a concept that occurs in the document is part of the sense;
- the sense is a generalization of a concept that occurs in the document;
- the sense is a specialization of a concept that occurs in the document.
The application of each test produces a matching score that indicates the algorithm’s level of confidence that the concept is present in the document. Tied scores can be presented to a domain expert for final classification. Each concept (Ci) is stored in an index and points to a list of the documents that contain the concept. For example:
- C1 ⇒ D1, D2, D3, D4
- C2 ⇒ D1, D2
- C3 ⇒ D1, D2, D3
- C4 ⇒ D1
The list of documents for each concept in the index is augmented with the score Mi of matching concept C with document Di:
C ⇒ {D1, M1}, {D2, M2}, {D3, M3}
The same Boolean operations can be applied to an index of concepts as for an index of keywords.
5.2 Identifying Query Concepts
The second stage of the concept IR model is to identify the concepts in a query. This must be performed each time a query is issued.
Typical keyword queries do not contain enough keywords to enable the algorithm described in the previous section to identify the concepts in a query. The most accurate method of identifying the concepts in a query is to harness the users’ language skills by asking them which senses of the query keywords were intended. The user interface of the search engine described in section 6 shows how the senses of a keyword can be disambiguated.
5.3 Matching Query and Document Concepts
The final stage of the concept IR model is to match the concepts in a query with the concepts in the documents. Documents are matched with queries using the concept ⇒ document index. The degree to which the concepts in a query match the concepts in the documents is represented by a numerical matching score that is used to rank the results.
The concept IR model is more flexible than the strict matching performed by the Boolean keyword model. The Boolean model partitions documents into two sets: those documents that contain the query keywords and those that do not. This strict partitioning does not fit well with natural language. The vector space model (Salton 1971) and rough sets (Srinivasan 1991) were developed to retrieve documents that partially match a query. The concept IR model enables documents to be retrieved that match queries in varying degrees.
Five matching rules—based on the relations described in section 3—are used to generate a matching score. The base rule is that the same sense of a keyword always matches itself.
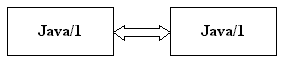
Synonyms of the same sense of a keyword always match.
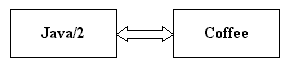
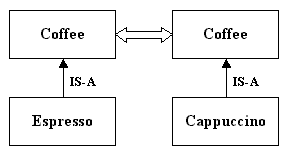
Concepts can be matched by the hyponym (generalization) relation. For example, espresso and cappuccino are both types of coffee, i.e. coffee is a generalization of both espresso and cappuccino. Concepts can be matched by applying a relation more than once.
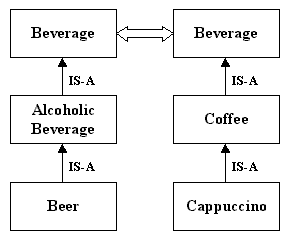
Similarly, beer is a type of alcoholic beverage and that cappuccino is a type of coffee. Alcoholic beverage and coffee are both types of beverage: beverage is a generalization of a generalization of beer and coffee.
Concepts can be matched by the meronym (part-of) relation. For example, Java and Bali are parts of Indonesia. Concepts can also be matched by more than one relation at once.
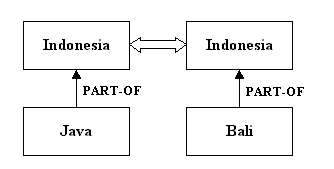
Java and Bali match Island with the hyponym relation, and match Indonesia with the meronym relation.
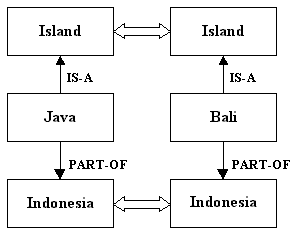
Two concepts, A and B, are matched in the following order:
- check if A = B;
- check if A is a synonym of B;
- check if A and B are part of the same concept;
- check if A and B have a common generalization;
- check if A is a generalization of B.
The relation that matches two concepts determines the matching score. For example, the meronym relation is stronger than the hyponym relation. Concepts that are part of a whole are more closely related that generalizations of those parts. Java is more closely related to Bali than to Australia, for example, because Java and Bali are part of Indonesia, even though they are all islands.
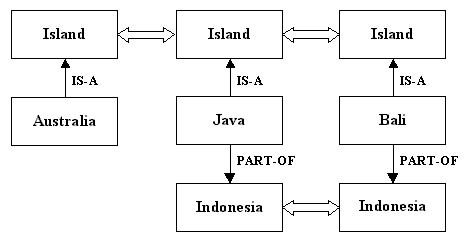
Matching scores are weighted by the relation used to match the concepts. The relations have different weights and are weighted in the following order, from highest to lowest:
- exact match;
- synonyms;
- parts;
- specializations;
- generalizations.
Matching scores are also weighted by the number of relations used to match the concepts; the larger the number of relations used, the lower the score. For example, espresso and cappuccino would have a higher matching score than beer and cappuccino even though the three concepts have a common generalization, beverage. Espresso and cappuccino are matched with one application of the hyponym relation, beer and cappuccino are matched with two applications.
This section has described how the concept IR model matches the concepts in a document collection with the concepts in a user query. The next section describes a prototype user interface for a concept IR system.
6. A User Interface for a Concept IR System
This section describes a prototype user interface for a web search engine based on a concept IR system. The user inputs a query and the search engine presents all the senses of the keywords in the query and enables the user to select the intended sense.
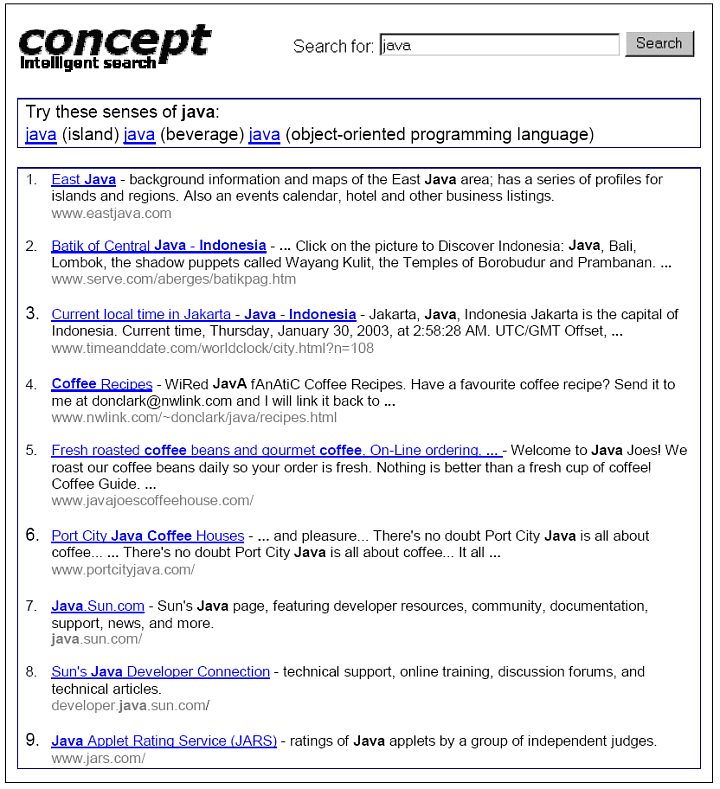
The following screenshot shows that the results of the single keyword query, Java, contain documents about all three senses of Java. The three senses are listed above the results. A link to the sense is presented next to an explanation of the sense. Clicking on a sense issues a new query that will retrieve the documents only for that sense.
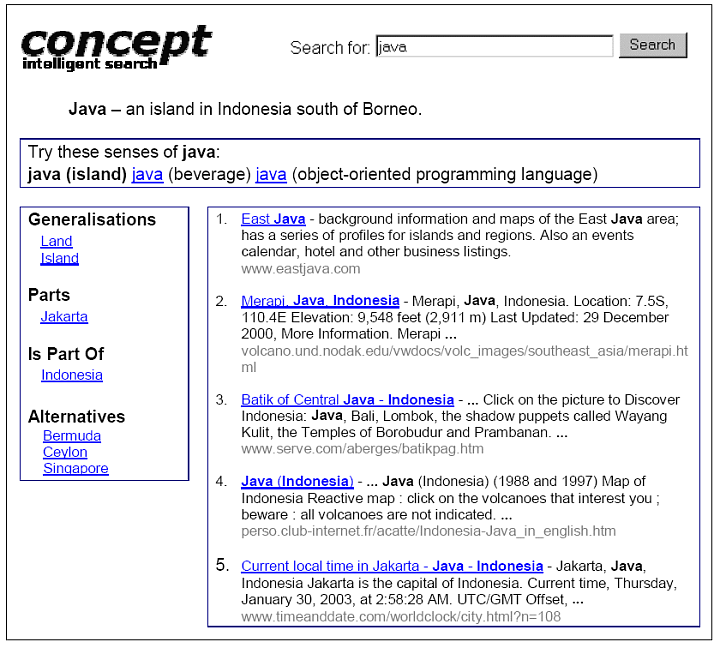
The next screenshot shows the results of clicking on the first sense of Java, the island in Indonesia.
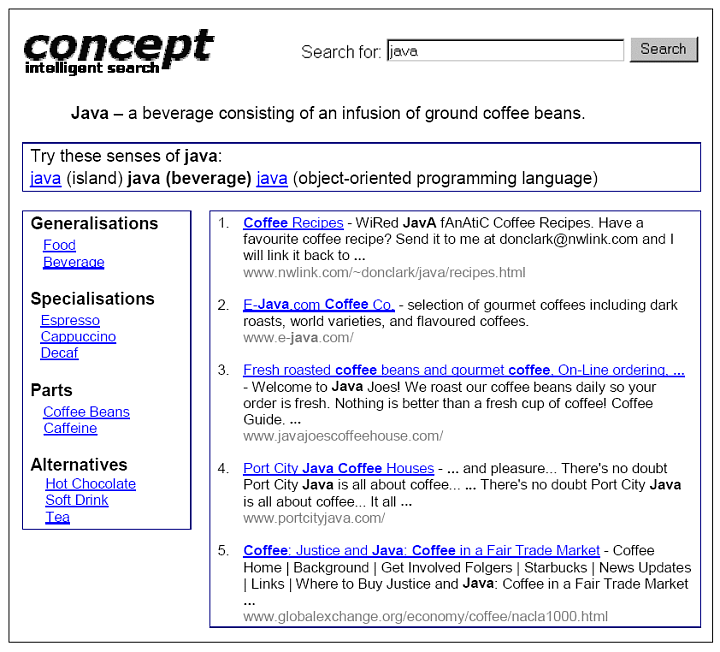
The following screenshot presents the results of clicking on the second sense of Java, the beverage.
The following screenshot the results of clicking on the third sense of Java, the object-oriented programming language.
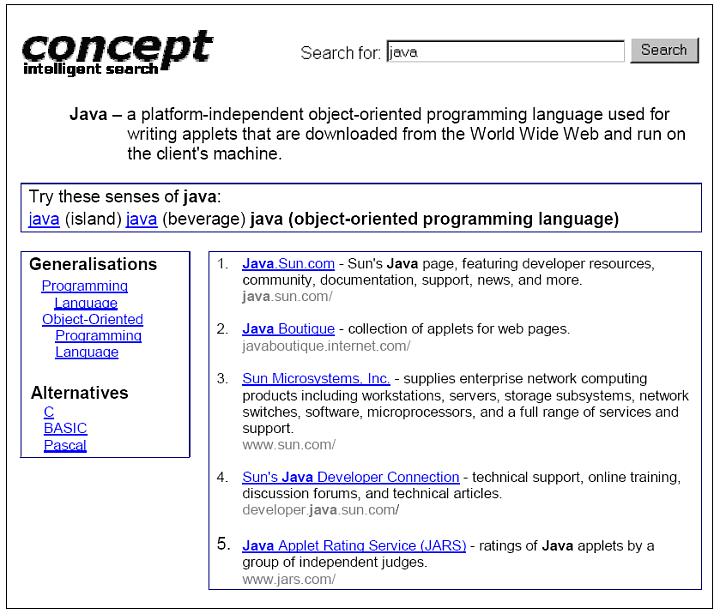
Users are able to navigate and search with the concept hierarchy with a point and click interface. The concept hierarchy is shown on the left hand side of of the above screenshots. Users can choose the other senses of the keyword java, the generalizations, the parts, and the whole of which it is a part.
Users can broaden or narrow a search by clicking on a generalization or a specialization, respectively. If there are too many results, users can click on a specialization. If there are too few results, users can click on a generalization.
The alternatives are the siblings of the current concept, i.e. the concepts that have the same generalization as the current concept.
References
- Fellbaum C., WordNet: An Electronic Lexical Database, MIT Press, 1998.
- Furnas, G. W., T. K. Landauer, L. M. Gomez, and S. T. Dumais, The vocabulary problem in human-system communications, Communications of the ACM 30(11), 1987: 964-971.
- Deerwester, S., S. T. Dumais, G. W. Furnas, T. K. Landaur and R. Harshman, Indexing by latent semantic analysis, Journal of the American Society for Information Science 41(6), 1990: 391-407.
- Greene, S. L., No IFs, ANDs, or ORs: A study of database querying, International Journal of Man-Machine Studies 32, 1990: 303-326.
- Lefkowitz, D., File Structures for On-Line Systems, Spartan Books, 1964.
- Miller, G. A., R. Beckwith, C. Fellbaum, D. Gross, and K. Miller, Introduction to WordNet: An On-Line Lexical Database, https://wordnetcode.princeton.edu/5papers.pdf, 1993.
- Ruge, G., Human memory models and term association, in E. A. Fox, P. Ingwersen and R. Fidel (eds), Proceedings of SIGIR ‘95;, 1995: 219-227.
- Salton, G., The SMART Information Retrieval System, Prentice-Hall, 1971.
- Spink, A., Term relevance feedback and query expansion: Relation to design, in W. B. Croft and C. J. van Rijsbergen (eds), Proceedings of SIGIR ‘94, 1994: 80-81.
- Srinivasan, P., The importance of rough approximations for information retrieval, International Journal of Man-Machine Studies 34, 1991: 657-671.
- van Rijsbergen, C. J., Information Retrieval, Butterworths, 1979.